PDF to Excel conversion: Your ultimate guide to the best tools
Need to extract data from PDF files into a spreadsheet so you can analyze it? Find out how seven PDF to Excel conversion tools fared in head-to-head tests with increasingly complex data sources.






Executive Editor, Data & Analytics, Computerworld |

- 3 questions to ask when choosing a PDF to Excel converter
- How we tested the converter tools
- PDF to Excel converters we tested
- PDF to Excel test results
- PDF conversion tools we didn’t test
In an ideal world, the data we need to analyze would be available in ready-to-use format. In the world we live in, though, a lot of valuable data is locked inside Portable Document Format (PDF) documents. How to extract that data from PDFs into an Excel spreadsheet? You have a number of PDF to Excel converters to choose from.
There’s software from major vendors like Microsoft and Adobe, task-specific cloud services including PDFTables and Cometdocs, services from general-purpose cloud providers such as Amazon, and even free open-source options.
Which is the “best” PDF to Excel converter? As with the “best computer,” the answer depends on your specific circumstances.
3 questions to ask when choosing a PDF to Excel converter
There are several important considerations when selecting a PDF converter.
1. Was my PDF generated by an application or is it a scanned image? There are two types of PDF files. One is generated by an application like Microsoft Word; the other comes from a scanned or other image file. You can tell which one you have by trying to highlight some text in the document. If a click and drag works to highlight text, your PDF is app-generated. If it doesn’t, you’ve got a scan. Not all PDF conversion tools work on scanned PDFs.
2. How complex is the data structure? Almost every tool will work well on a simple one-page table. Things get more complicated if tables are spread over multiple pages, table cells are merged, or some data within a table cell wraps over multiple lines.
3. Do I have a large volume of files that need batch file conversions or automation? Our best-performing tool on app-generated PDFs may not be the best choice for you if you want to automate frequent batch conversions.
In addition, as with any software choice, you need to decide how much you value performance versus cost and ease of use.
How we tested the converter tools
To help you find what’s best for your tasks, we tested seven PDF to Excel conversion tools using four different PDF files ranging from simple to nightmare. You’ll see how all the tools perform in each scenario — and find out the strengths and weaknesses of each one.
PDF to Excel converters we tested
Here are the tools we tested, starting with our overall best performers (but remember that “best” depends in part on the specific source document). All these tools did pretty well on at least some of our tasks, so rankings range from “Excellent” to “Good.”
Adobe Acrobat Export PDF subscription
As the creator of the Portable Document Format standard, you’d expect Adobe to do well in parsing PDFs — and it does. A full-featured conversion subscription is somewhat pricey, but there’s also an inexpensive $2/month plan (annual subscription required) that includes an unlimited number of PDF to Excel conversions. (You can output Microsoft Word files with this tool as well).
The Excel conversions include any text on pages that have both text and tables. This can be a benefit if you’d like to keep that context or a drawback if you just want data for additional analysis.
Rating: Excellent — our hands-down winner for non-scanned PDFs.
Cost: $24/year
Pros: Outstanding results; preserves much of the original formatting; deals well with tables spanning multiple pages; unlimited conversions of files up to 100MB; affordable for frequent users.
Cons: No built-in scripting/automation workflow; expensive if you only convert a few documents a year.
Bottom line: If you don’t need to script or automate a lot of conversions and don’t mind paying $24 per year, this is a great choice.
Amazon AWS Textract
For an AWS cloud service, Textract is surprisingly easy to use. While you certainly can go through the usual multi-step AWS setup and coding process for Textract, Amazon also offers a drag-and-drop web demo that lets you download results as zipped CSVs. You just need to sign up for a (free) Amazon AWS account.
Rating: Excellent — this was our best option for a complicated scanned PDF.
Cost: 1.5 cents per page (100 pages per month free for your first three months at AWS)
Pros: Best option tested for a complicated scanned PDF; performed extremely well on all the app-generated PDFs; offers a choice of viewing results with merged or unmerged cell layout; easy to use; affordable.
Cons: Uploaded files are limited to 10 pages at a time. For those who want to automate, using this API is more complicated than some other options.
Bottom line: An excellent choice if you don’t mind the AWS setup and either manual upload or coding with a complex API.
Tabula
If you’re looking for free and open source, give Tabula a try. Unlike some free options from the Python world, Tabula is easy both to install and to use. And it has both a command-line and a browser interface, making it equally useful for batch conversions and point-and-click use.
Tabula did very well on PDFs of low or moderate complexity, although it did have an issue with the complex one (as did many of the paid platforms). Tabula requires a separate Java installation on Windows and Linux.
Rating: Very good — and you can’t beat the price.
Cost: Free
Pros: Free; easy to install; has both a GUI and scripting options; allows you to manually change what areas of the page should be analyzed for tables; can save results as a CSV, TSV, JSON, or script; offers two different data extraction methods.
Cons: Needed some manual data cleanup on complex formatting; works on app-generated PDFs only.
Bottom line: A good choice if cost, ease of use, and automation options are high on your list of desired features and your PDFs aren't scanned.
PDFTables
A key advantage to this service is automation. Its API is well documented and supports everything from Windows PowerShell and VBA (Office Visual Basic for Applications) to programming languages like Java, C++, PHP, Python, and R.
PDFTables performed well on most of the app-generated PDF tables, even understanding that a two-column header would be best as a single-column header row. It did have some difficulty with data in columns that were mostly empty but also had some data in cells spread over two lines. And while it choked on the scanned nightmare PDF, at least it didn’t charge me for that.
Rating: Very good overall; excellent on automation.
Cost: 50 pages free at signup — including API use. After that it’s $40 for up to 1,000 pages, and your credits are only good for a year.
Pros: Very good API; better performance on the moderately complex PDF than several of its paid rivals.
Cons: Pricey, especially if you use more than the 50 free pages but less than 1,000 page conversions in a year. Doesn’t work on scanned PDFs.
Bottom line: Performs well and is easy to use both on the web and through scripting and programming. If you don’t need an elegant API, however, you may prefer a less expensive option.
PDFtoExcel.com
This is a freemium platform with paid options. It proved to be the lone free choice that was able to handle our scanned nightmare PDF.
Rating: Good.
Cost: Free in the cloud, $5/month or $49/year premium cloud for batch conversions and faster service, desktop software $35 for 30-day use or $150 lifetime.
Pros: A lot of capability for the free option; works on scanned PDFs; affordable.
Cons: No API or cloud automation (we didn’t test the desktop software); paid option required for batch conversions; split single-row multi-line data into multiple rows.
Bottom line: Nice balance of cost and features. This was most compelling for complex scanned PDFs, but others did better when cell data ran across multiple lines.
Cometdocs
This web-based service is notable for multiple file format conversions: In addition to generating Excel, it can download results as Word, PowerPoint, AutoCAD, HTML, OpenOffice, and others. Free accounts can convert up to five files per week (30MB each); paid users get an unlimited number of conversions (2GB/day data limit).
Cometdocs is a supporter of public service journalism; the service offers free premium accounts to Investigative Reporters & Editors members (disclosure: I have one).
Rating: Good.
Cost: 5 free conversions/week; otherwise $10/month, $70/year or $130 “lifetime.”
Pro: Works on scanned PDFs; multiple input and output formats; generally good results; did extremely well on a 2-page PDF with complex table format.
Cons: Not as robust on complex scanned PDFs as some other options; split one row’s multi-line data into multiple rows; no clear script/automation option.
Bottom line: Particularly compelling if you're interested in multiple format exports and not just Excel.
Microsoft Excel
Many people don’t know that Excel can import PDFs directly — but only if you’ve got a Microsoft 365 or Office 365 subscription on Windows. It was a good choice for the simple file but got more cumbersome to use as PDF complexity rose. It’s also likely to be confusing to people who aren’t familiar with Excel’s Power Query / Get & Transform interface.
How to import a PDF directly into Excel: In the Ribbon toolbar, go to Data > Get Data > From File > From PDF and select your file. For a single table, you’ll likely have one choice to import. Select it and you should see a preview of the table and an option to either load it or transform the data before loading. Click Load and the table will pop into your Excel sheet.
For a single table on one page, this is a quick and reasonably simple choice. If you have multiple tables in a multi-page PDF, this also works well — as long as each table is confined to one page. Things get a bit more complex if you’ve got one table over multiple PDF pages, though, and you’ll need knowledge of Power Query commands.
It’s somewhat unfair to compare Power Query data transformation with the other tools, since the results of any of these other PDF to Excel converters could also be imported into Excel for Power Query wrangling.
Rating: Good.
Cost: Included in a Microsoft 365/Office 365 Windows subscription.
Pro: You don’t have to leave Excel to deal with the file; a lot of built-in data wrangling available for those who know Power Query.
Cons: Complex to use compared with most others on all but the simplest of PDFs; doesn’t work on scanned PDFs; requires a Microsoft 365/Office 365 subscription on Windows.
Bottom line: If you’ve already got Microsoft 365/Office 365 on Windows and you’ve got a simple conversion task, Excel is worth a try. If you already know Power Query, definitely consider this for more PDF conversions! (If you don’t, Power Query is a great skill to learn for Excel users in general.) If your PDF is more challenging and you don’t already use Power Query / Get & Transform, though, you’re probably better off with another option.
PDF to Excel test results
Here’s how the seven tools fared in our four conversion tests:
1. Simple PDF to Excel challenge
Our “simple” task was a single-page app-generated PDF pulled from page 5 of a Boston housing report. It contained one table and some text, but column headers and two data cells did include wrapped text over two lines.
All the platforms we tested handled this one well. However, several broke up the multi-line text into multiple rows. The issue was easy to spot and fix in this example, but this issue could be difficult in larger files. For this easy one-pager, though, the PDF to Excel converters that weren’t in first or second place still had very good results. All were worth using for this type of conversion.
First place: Tie — Adobe and AWS Textract. With Adobe, no data cleanup was needed. The column headers even had the color formatting of the original. Adobe’s conversion included text (with lovely formatting), which is useful if you want to keep written explanations together with the data in Excel. You’d need to delete the text manually if you want data only, but that’s simple enough.
AWS Textract converted data only. No data cleanup was needed.
Close second: Excel. Data only. Excel didn’t break wrapped text into two rows, but it did appear to run text together without a space with multi-line rows. The data was actually correct, though, when you looked at it in the formula bar — it just looked wrong in the overall spreadsheet. This was easily fixed by formatting cells with "wrap text." However, not everyone might know to do that when looking at their spreadsheet.
Others:
PDFTables: returned data and text. Same issues as Excel with appearing to keep wrapped text in a single line without a space between words. This was also easily fixed by wrapping text, if you knew to do so. This result also would need cleanup of a couple of words from a logo that appeared below the data. Explanatory text outside the logo had no problems, though.
Tabula: data only. Split multi-line cells into multiple rows.
Cometdocs: data and text. Split multi-line cells into multiple rows. Surrounding text was accurate, including logo text.
PDFtoExcel.com: similar performance to Cometdocs.
2. Moderate PDF to Excel challenge
Our moderate PDF challenge was a single app-generated table spanning multiple PDF pages, via the Boston-area Metropolitan Water Resources Authority data monitoring wastewater for Covid-19 traces.
First place: Adobe. One of the few to recognize that all the pages were the same table, so there were no blank rows between pages. Headers were in a single row and spaces between words in the column names were maintained. Data structure was excellent, including keeping the multi-line wrap as is. It even reproduced background and text colors. The 11-page length wasn’t a problem.
Second: AWS Textract. Header row was correct. Each page came back as a separate table, although it would be easy enough to combine them. The one strange issue: There were apostrophes added at the beginning of the cells — possibly due to how I split the PDF, since I needed to create a file with only 10 pages. However, those apostrophes were easy to see and remove with a single search and replace, since the data didn’t include any words with apostrophes. It was easier to get the exact data I needed than with Tabula, but more cumbersome to get the full data set.
Close third: Tabula. No blank rows between pages, data in the correct columns, wrapped cells stayed in a single row. Unfortunately, while the wrapped data appeared properly when you looked at the cell contents in the formula bar, once again the data appeared to merge together in the full spreadsheet — and this wasn’t as easily fixed by formatting with text wrapping as with Excel and PDFTables in the simple PDF.
For example, this was the content of one cell as it appeared in the formula bar:
B.1.1.7
76%
But in the overall spreadsheet, that same cell looked like
B.1.1.776%
I was able to get that to display properly at times by increasing the row height manually, but this was an added step that most people wouldn’t know to do, and it didn’t seem to work all the time.
Others:
PDFtoExcel.com: multiple problems. The first few pages were fine except for multi-row headers, but data over two lines in single cells broke into two rows in the data, generating blank rows elsewhere that would need to be fixed. In addition, columns were shifted to the right in one section. This would need cleanup.
PDFTables: multiple problems. All the data came in fine for most of the pages, but toward the end, a few cells that should have been in column J got merged with column I in ways that would be more difficult to fix than PDFtoExcel’s. For example, this single cell:
Omicron
559 23%
Was supposed to be 559 in one cell and Omicron 23% in the next cell.
Cometdocs: failed. Conversion failed on the full PDF and even the 10-page version I uploaded to AWS. It was able to convert a version with just the first 5 pages, but the full file should have been well below Cometdoc’s account limits.
Excel: it was possible to get the data in a format I wanted, but it required data manipulation in Power Query as well as wrapping text. That’s not a fair comparison with other platforms that were a single upload or command. Still, results were ultimately excellent. If you’re an Excel/Power Query power user, this is a good choice.
3. Complex PDF to Excel challenge
Local election results are some of my favorite examples of analysis-hostile public data. The app-generated PDF from Framingham, Mass. shown below was only 3 pages but with table formatting that was not designed for ease of data import. Is there a PDF conversion tool that can handle it?
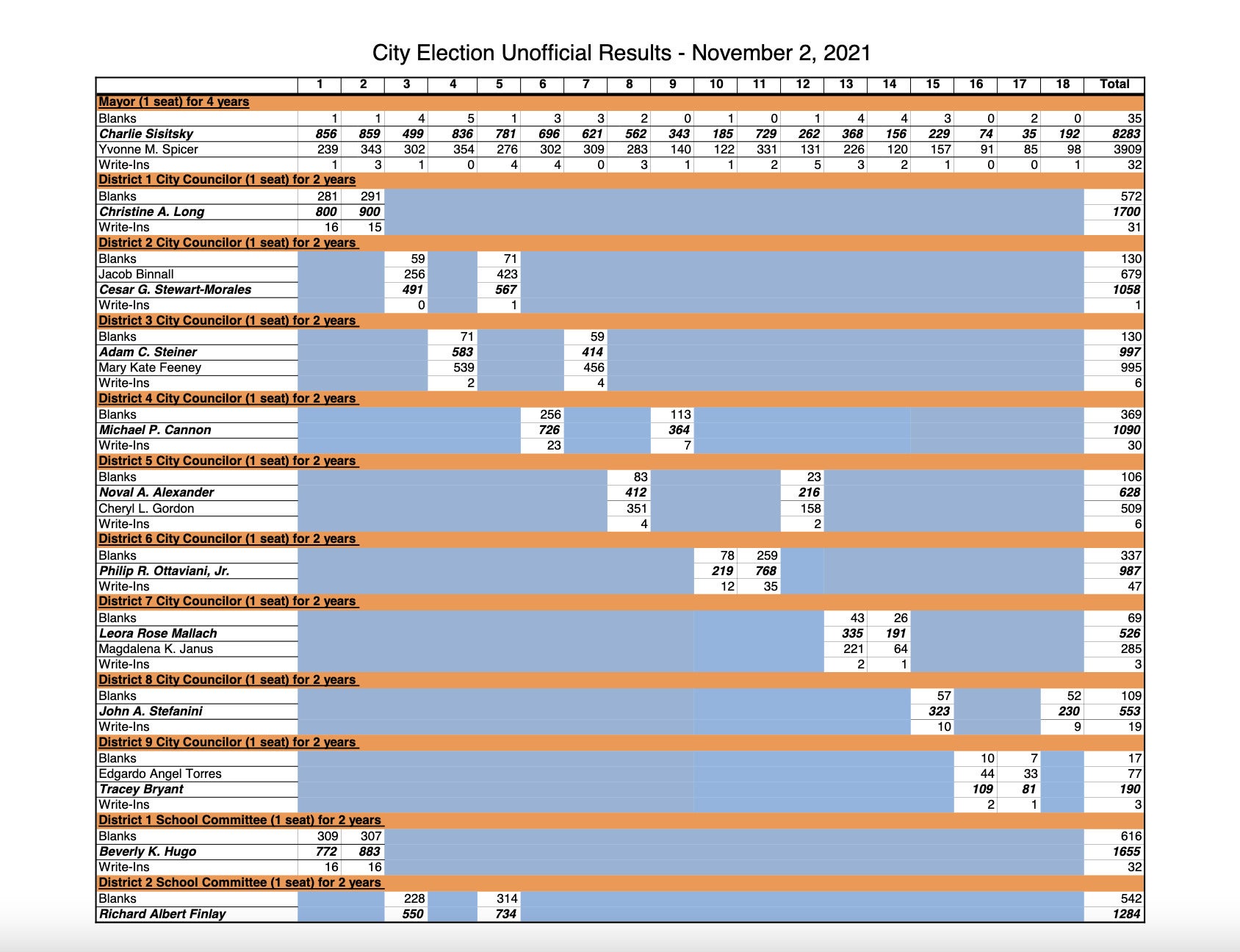 IDG
IDG
Page 1 of the PDF showing recent election results for Framingham, Mass. (Click image to enlarge it.)
First place: Tie — Adobe and PDF to Excel. Adobe returned an Excel file in perfect format, complete with original cell colors.
While PDFtoExcel.com’s spreadsheet didn’t have the pretty formatting of Adobe, all the data came in accurately, and it was usable as is.
Others:
AWS Textract: fair. Results came back in 5 tables. In one case, you’d need to copy and paste them together manually and look at the original to make sure you were doing so correctly.
PDFTables: poor. Data came back, but some in the wrong columns, whether I tried to download as multiple sheets or one sheet. This would need manual checking and cleanup.
Tabula: poor. Similar problem as PDFTables with some data in the wrong columns, but at least I didn’t have to pay for it. I tried both the Stream and Lattice extraction methods, and both had some wrong-column issues (although the issues were different).
Cometdocs: conversion failed.
4. Nightmare PDF to Excel challenge
Our nightmare comes courtesy of a presentation at this year's National Institute for Computer Assisted Reporting conference, as an example of data that would be useful for training students — if it was in a format that could be easily analyzed. It’s a multi-page scanned PDF with four months of data from the federal Refugee Processing Center on refugee arrivals by country of origin and U.S. state of destination.
This PDF’s challenges range from multi-page tables to lots of merged columns. In addition, the table on page 1 proved to be somewhat different than tables on the other pages, at least in terms of how several tools were able to handle them, although they look the same.
I only tested the first 10 pages due to the AWS 10-page limit, to be fair to all the tools.
First place: AWS Textract. By far the best of the group. This is where sophisticated machine learning is an advantage. Results are download as a zipped file of multiple CSVs, one for each page. Instead of manually importing those files one by one into Excel, though, you can go to Data > Get Data > From File > From Folder and select the folder with those newly unzipped CSVs (without a few extra files, such as one with metadata and another with all the text in text format).
I also had to rename file table-10 to table-910, because the import was putting table-10 right after table-1 and before table-2 (sorting the filenames alphabetically and not -9 after -10). While I didn’t check all the data, the rows I spot-checked were all accurate. This was the easiest way to collect all the pages into a single, usable spreadsheet.
Second: Tie — Cometdocs and PDFtoExcel.com. Cometdocs had unexplained “Grand” lines on each of the pages — a single row just with “Grand” in the first column — but otherwise the data looked very good. And it came in a single file.
Including text on each page could be a benefit or drawback, depending on your needs. Context is useful, but combining the data into one table would definitely take more work.
PDFtoExcel.com’s performance was similar to Cometdocs — including the extra “Grand” lines.
Others:
Adobe: fair. While a lot of the data was fine, results merged some data on the first page and would need manual checking and cleanup.
PDFTables: does not work on scanned PDFs without using OCR software first — although at least it doesn’t charge account credits when tables aren’t detected.
Tabula: does not work on scanned PDFs without using OCR software first.
PDF conversion tools we didn’t test
There are a number of other useful tools out there that require a bit more setup work or some significant coding in order to turn your PDF into data you can analyze. If none of the ones we tested work for you, though, here are a few others:
Excalibur: I received a tip about this one, a web interface built for the Camelot Python library. However, it involves installing several dependencies, and that installation may be a turn-off for people who don’t already have Python experience (even though you don’t need to run Python in order to use it).
Google Cloud Document AI: Google Cloud’s Document AI setup is significantly more involved than using AWS Textract. Plus, while you can upload a test document up to 5 pages to see what’s extracted, I didn’t see an obvious way to download the results through the web interface as a CSV or Excel file — the only option was JSON. You’d probably need a programming language like Python or R to use this effectively.
Microsoft Azure Form Recognizer: This is also more complex to set up than AWS Textract, but if you’re already an Azure user, it's probably worth a look. 500 free pages per month.
Copyright © 2022 IDG Communications, Inc.